Appearance
Managing the data model
Introduction
Each data model describes its:
- Source of data: a database table or a SQL query
- Fields: the columns present on this data model
- Relations: relationships to other data models
TIP
To benefit from auto-completions and linting when editing Supersimple configuration files, include the # yaml-language-server... line as shown in the examples below.
Your editor might also require an extension, like YAML for VSCode.
yaml
# yaml-language-server: $schema=https://assets.supersimple.io/supersimple_configuration_schema.json
models:
account:
name: Account
table: user_accounts
primary_key:
- account_id
properties:
account_id:
name: Account ID
type: String
name:
name: Name
type: String
payment_plan:
name: Payment Plan
type: Enum
enum_options:
load: distinct_values
created_at:
name: Created At
type: Date
relations:
users:
name: Users
type: hasMany
model_id: user
join_strategy:
join_key: account_id
onboarding_response:
name: Onboarding Response
type: hasOne
model_id: onboarding_response
join_strategy:
join_key: account_idConfiguration files can use either a multi-entity format (e.g. models: with a map of model IDs) or a single-entity format (e.g. model: with a model_id field inside). This makes it easy to manage each model, metric, or exploration in its own file.
Importing data models
While data models are managed as YAML files and can be stored wherever you choose (most customers use a Git repo for this), they get imported into Supersimple using our CLI.
- Install the CLI (this is how to do it on macOS using Homebrew)
sh
brew tap gosupersimple/cli
brew install supersimple- Log in to your account:
sh
supersimple login- Import the data model file(s) using
sh
supersimple import my_model_file.yamlTIP
For a much more detailed overview of using the CLI, as well as installing it on other platforms, please see our guide to using the CLI.
Model data source
Each data model must define its data source by specifying either a database table or an SQL query.
Table
models.<model>.table
yaml
models:
account:
name: Account
# use the whole table as-is
table: myschema.accountSQL
models.<model>.sql
yaml
models:
invitation:
name: Invitation
sql: SELECT * FROM invitation WHERE sent_at IS NOT NULL
# multi-row SQL example
invoice:
name: Invoice
sql: |-
SELECT
id,
amount / 100 AS amount_usd
FROM myschema.invoice_rawPrimary key
models.<model>.primary_key
Setting the primary key on a model automatically enables links to that data model's detail view. It is set as an array of primary key columns.
A primary key is not strictly required, but should be set whenever it logically exists in the data model.
yaml
models:
account:
table: myschema.account
primary_key:
- account_idName & description
models.<model>.name and models.<model>.description
Set an user friendly name and model description to be displayed in the user interface.
Properties
models.<model>.properties
Sets the properties (aka Fields) that a model has. Properties must be listed explicitly in order to be shown on the platform.
Properties that are present in the data source (returned by the model's configured database query) but not in the properties list will not be visible to users.
Name & description
models.<model>.properties.<property>.name and models.<model>.properties.<property>.description
Set user friendly name and property description to be displayed in the user interface wherever working with model properties.
Property type
models.<model>.properties.<property>.type
Properties can have the following type:
StringEnumNumberIntegerFloatBooleanDateArrayObjectInterval
yaml
models:
account:
table: myschema.account
properties:
account_id:
name: Account ID
type: String
name:
name: Name
type: String
created_at:
name: Created At
type: Date
is_active:
name: Active
type: BooleanProperty format
models.<model>.property.<property>.format
You can also specify a display format for properties of a certain type:
percentageFloat:0.01is displayed as1.00%eurNumber, Float, Integer: e.g.€1,000.00according to your device's locale settingsusdNumber, Float, Integer: e.g.$1,000.00according to your device's locale settingsgbpNumber, Float, Integer: e.g.£1,000.00according to your device's locale settingsmxnNumber, Float, Integer: e.g.$1,000.00according to your device's locale settingscadNumber, Float, Integer: e.g.$1,000.00according to your device's locale settingsdateDate: e.g.Oct 28th 2024according to your device's locale settingstimeDate: e.g.16:08according to your device's locale settingsisoDate: e.g.2021-01-01T12:00:00ZrawRemoves all formatting (e.g. numbers are by default formatted according to your device's locale settings). This is automatically applied to primary keys and join keys.
Enum options
models.<model>.properties.<property>.enum_options
Available options for properties of Enum type can be specified as follows. Although optional, enum options greatly improve the usability of composing query steps in the user interface.
Static options
Options can be defined directly in model definition by defining list of static options using the load: static parameter. For static options it is required to list all available enum options using the options array.
yaml
models:
user:
properties:
role:
type: Enum
enum_options:
load: static
options:
- value: ADMIN
label: Admin
- value: USER
label: UserDynamic options
Options can be loaded on-demand from the data source by using distinct values of a model property. Dynamic options can be defined using load: distinct_values option. Additional properties can be provided:
modelmodel name to be used to query the options from. Defaults to current model when omitted.value_keymodel property to be used as option value. Defaults to the current property when omitted.label_keymodel property to be used as option label. Defaults to thevalue_keywhen omitted.cache_ttltime-to-live for the cache of the options. Defaults to6 hourswhen omitted. Valid units areminutes,hoursanddays.
yaml
models:
user:
properties:
country_code:
type: Enum
enum_options:
load: distinct_values
model: country
value_key: country_code
label_key: name
cache_ttl: 72 hoursINFO
The list of dynamic enum options is limited to 1000 values maximum. Values are sorted alphabetically by value_key and may be truncated if the query returns more than 1000 distinct values.
Relations
models.<model>.relations
Relations describe how different data models are linked together. Relations:
- Encapsulate the semantic meaning of the relationships – two data models might have several relationships between each other, with different meanings (e.g. a Person might have multiple relations to other Persons: friends and enemies)
- Centrally define the SQL join logic
Relations are, by default, unidirectional. They are defined from the "base model" – the data model from which you can use them. For example, for an User's Car, User would be the base model, and Car would be the related model.
hasMany
Each row in the base model has zero or more (up to infinity) matches in the related model (e.g. Company->Employee)
yaml
models:
...
company:
...
relations:
employees:
name: Employees
type: hasMany
model_id: employee
# Optional, can be used to add filters on related model
operations: []
join_strategy:
join_key_on_base: company_id
join_key_on_related: company_idFor using operations, see the operations reference below.
Tip: join_key
When both sides of the relation share the key with the same name, use join_key instead of explicitly defining both join_key_on_base and join_key_on_related:
yaml
join_strategy:
join_key: company_idTip: sql
Custom SQL for JOIN ON ... can be provided with sql property:
yaml
join_strategy:
sql: {{base_model}}.company_id != {{related_model}}.company_idUse {{base_model}} and {{related_model}} placeholders to reference base and related model names, respectively.
hasOne
Each row in the base model has exactly one match in the related model, or it has none at all (e.g. Employee->Employer)
yaml
models:
...
employee:
...
relations:
employees:
name: Employer
type: hasOne
model_id: company
join_strategy:
join_key_on_base: company_id
join_key_on_related: company_idmanyToMany
Functions just like hasMany; each row in the base model has zero or more matches in the related model (e.g. User->Team where every user can be in multiple teams and every team can have multiple users)
yaml
models:
...
team:
...
relations:
users:
name: Users
type: manyToMany
model_id: user
join_strategy:
through:
model_id: supersimple_user_in_team
# Optional, can be used to add filters on intermetiate model
operations: []
join_key_to_base: team_id
join_key_to_related: user_id
join_key_on_base: team_id
join_key_on_related: user_idFor using operations, see the operations reference below.
hasOneThrough
Functions just like hasOne; the underlying database has an intermediary table (e.g. a Person's Grandfather is defined through Person->Parent->Parent)
yaml
models:
...
person:
...
relations:
# This relation is used in the definition of the next relation
father:
name: Father
type: hasOne
model_id: person
join_strategy:
join_key_on_base: father_id
join_key_on_related: person_id
grandfather:
name: Grandfather
type: hasOneThrough
model_id: person
join_strategy:
steps:
# This uses the relation defined above
- relation_key: fatherTIP
Note that you only need to define one level of relations between data models. It's always possible to later dynamically traverse through your entire data graph, e.g. going from accounts to their users, to the users' analytics events.
Model semantics
models.<model>.semantics
For certain kinds of data models that almost every B2B SaaS company has, such as accounts, users and analytics events, you can describe additional semantic properties about the data models.
These later make it easier to do complex things like cohort retention analysis, without having to worry about database tables or configuring anything.
Account model semantics
Set kind as Account and define which model property specifies its creation time.
yaml
models:
account:
semantics:
kind: Account
properties:
created_at: created_atUser model semantics
Set kind as User and define which model property specifies its creation time.
yaml
models:
user:
semantics:
kind: User
properties:
created_at: created_atEvent model semantics
Set kind as Event and define which model property specifies event occurrence time.
yaml
models:
analytics_event:
semantics:
kind: Event
properties:
created_at: created_atLabels
models.<model>.labels
Add free-form metadata to models with labels. They appear next to the model in the models list. Model labels is a simple key-value object:
yaml
models:
account:
labels:
my_key: My Label
section: GeneralSystem-supported labels
Some of the labels provide additional functionality in the user interface.
sectiongroups models into sections by its value in the user interface
Metrics
Metrics allow you to reuse calculation logic in a flexible way. Metrics correspond to a single base model, and can be used from anywhere that has access to that data model. A metric can also be broken down (grouped) by any of that data model's Fields.
In your models YAML file, you can define metrics as follows:
yaml
metrics:
transaction_gmv:
name: GMV
model_id: transaction
aggregation:
type: sum
key: amountThe Metric can then be used as described under summarization options.
Metrics with more complex logic
Oftentimes, your Metrics will require more complex logic in addition to a single aggregation, such as filtering or even creating helper columns. For this, you can use any combination of our exploration steps (described in YAML) to define the logic of your Metric.
For complete list of available operations, see the operations reference below.
For example, you can define a Metric that only considers the GMV of Enterprise accounts:
yaml
metrics:
transaction_enterprise_gmv:
name: Enterprise GMV
model_id: transaction
operations:
- operation: addRelatedColumn
parameters:
relation:
key: account
columns:
- key: payment_plan
property: # This is the property we will be able to access in the next step
key: account_payment_plan # This is the key we will use to access the property
name: Account Payment Plan # Human-readable name
- operation: filter
parameters:
key: account_payment_plan
operator: ==
value: enterprise
aggregation:
type: sum
key: amount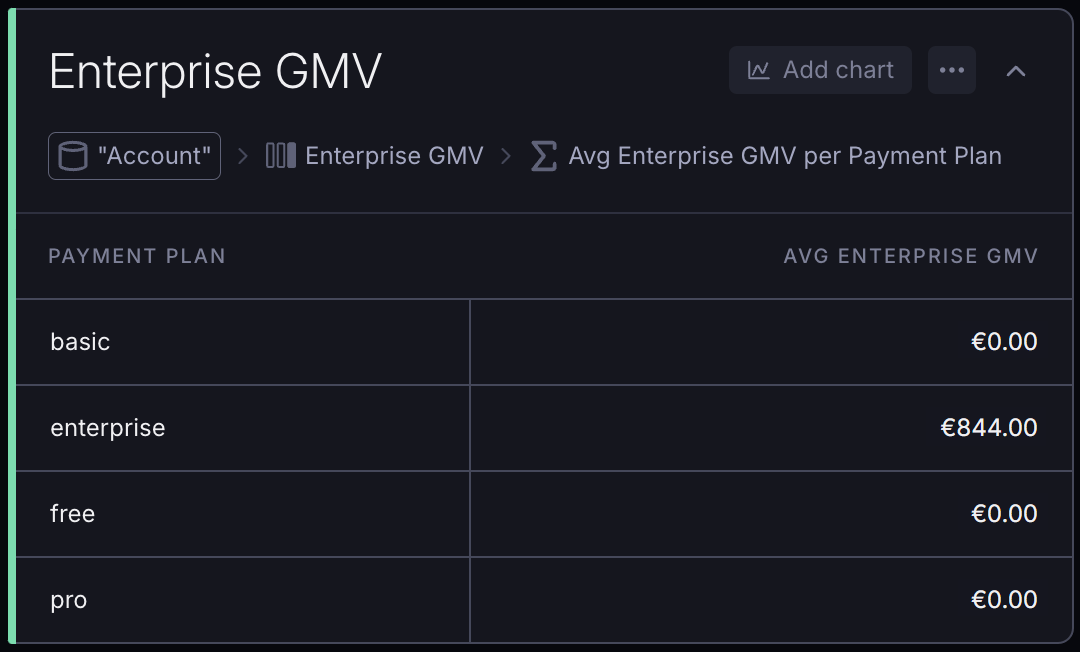
See the operations reference section below for more information on how to structure the operations used here.
Extending models
Using operations
You can also use the "no-code exploration steps" that you'd normally use in the UI to create new data models. While our YAML schema autocompletion will assist you with the syntax, you can also use our UI to get the YAML for any exploration block:
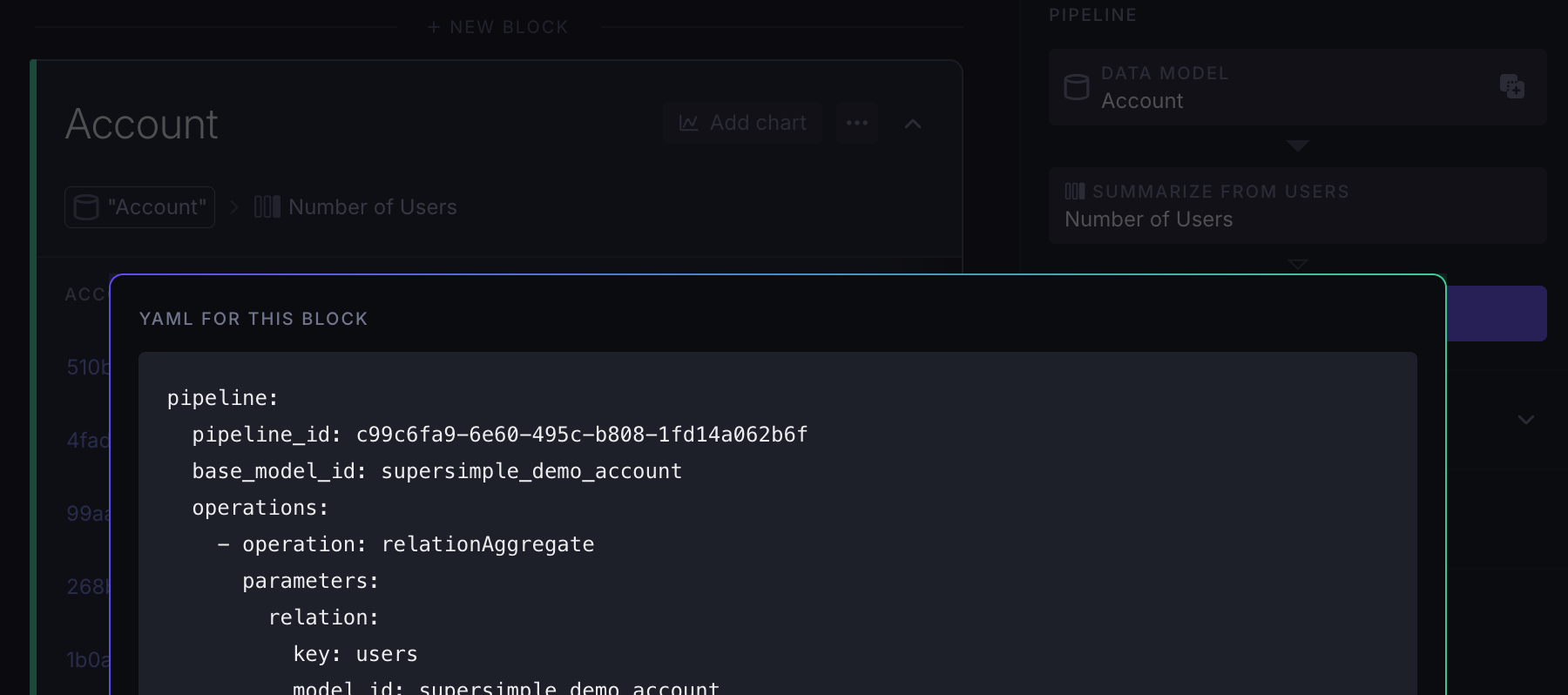
Applying operations to raw data
models.<model>.operations
Here, we use the account database table as a base, define a relation called users and use that relation itself to add the calculated column Number of users right into the model.
For complete list of available operations, see the operations reference below.
yaml
models:
account:
name: Account
table: account
operations:
- operation: relationAggregate
parameters:
relation:
key: users
aggregations:
- type: count
property:
name: Number of users
key: number_of_users
properties:
# List any properties here, except for ones created by
# the above "operations". In this case, `number_of_users`
# will be automatically recognized as a property, and
# does not need to be listed here manually.
account_id:
name: Account ID
type: String
relations:
users:
# This is the relation that we are using above
name: Users
# ... rest of the relation definitionAs a result, you would see a data model like this in the UI: it would have the Number of users property, without showing any steps/operations in the sidebar:
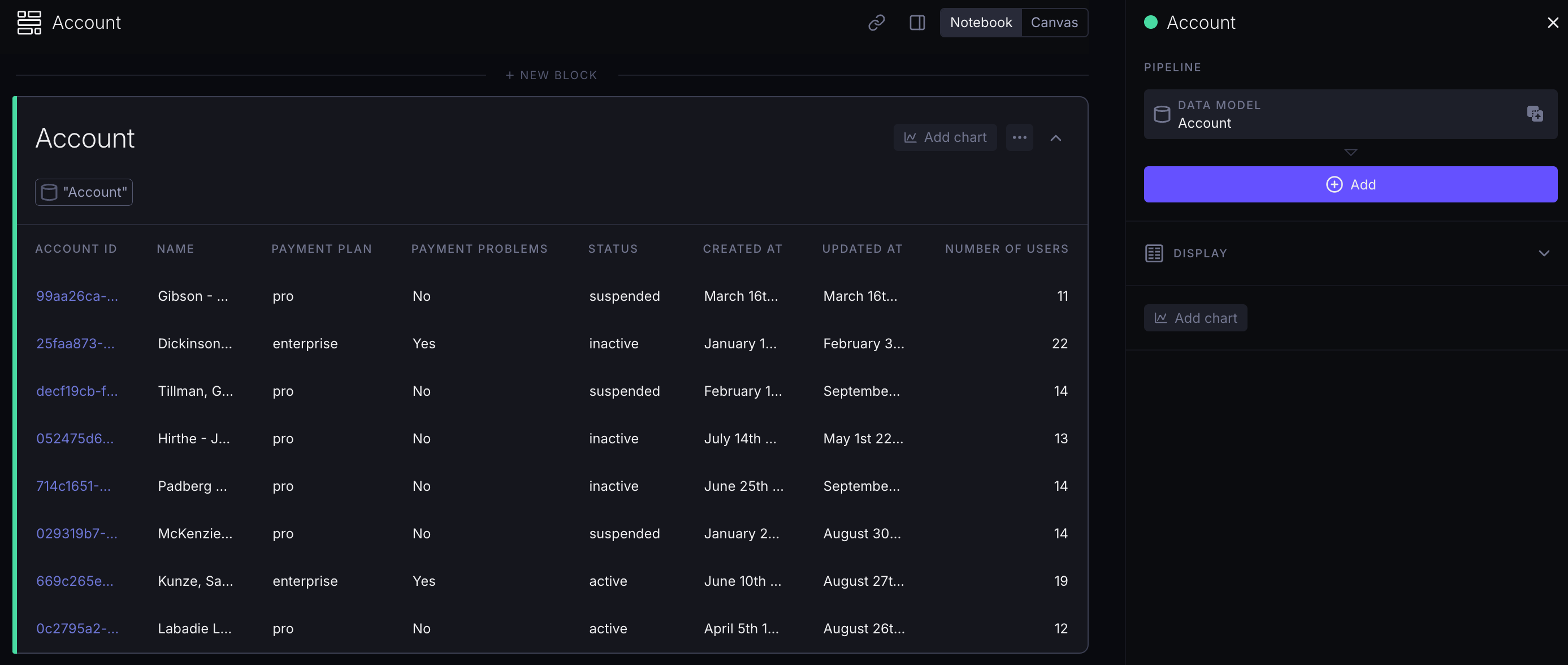
TIP
The "operations" used are not visible in the sidebar as steps.
Building models on top of other models
models.<model>.base_model
You can also define models "on top of" other models, instead of raw database tables or SQL queries. Here, we are building on top of the already-defined user model:
yaml
models:
users_with_many_large_transactions:
name: Users with many large transactions
# Inherit properties from and add operations to user model
base_model: user
operations:
# First create a column ...
- operation: relationAggregate
parameters:
relation:
key: transactions
aggregations:
- type: count
property:
name: Number of large transactions
key: number_of_large_transactions
filters:
- parameters:
key: amount
operator: ">"
value: 1000
# ... and use that column to filter
- operation: filter
parameters:
key: number_of_large_transactions
operator: ">"
value: 100
# All properties from the `user` base model are auto-included
# so there's no need to doubly define them here.
# All properties created in `operations` are also auto-included.
properties: {}The resulting data model would then have the Number of large transactions property and only includes the filtered-down rows, without showing any steps/operations in the sidebar.
TIP
You can use this to create more specialized versions of existing data models, or to apply filtering that you want to always be present (preventing users from forgetting to apply it).
Difference between no-code steps and operations
You'll notice slight differences in naming between the YAML format and the step names in the UI (for example: New column corresponds to multiple different operations in order to provide a clearer API).
Because of this, it's always easiest to use the UI to generate the relevant YAML wherever possible.
Operations reference
filter
Add filter to the data set returned by previous operations. Filter can be either a simple filter by value or composite filter containing multiple AND and OR operations.
| Parameter | Description |
|---|---|
key | Key of a result set property this filter applies to |
operator | One of ==, !=, <, <=, >, >=, icontains, noticontains, arrcontains, isnull, isnotnull, isempty, isnotempty |
value | Either string, number, boolean value or formula expression. See also custom formulas documentation. |
yaml
operation: filter
parameters:
key: account_id
operator: "=="
value: account-1yaml
operation: filter
parameters:
key: is_cancelled
operator: "!="
value: falseyaml
operation: filter
parameters:
key: number_of_users
operator: "<"
value: 10yaml
operation: filter
parameters:
key: number_of_users
operator: "<="
value: 10yaml
operation: filter
parameters:
key: number_of_users
operator: ">"
value: 10yaml
operation: filter
parameters:
key: number_of_users
operator: ">="
value: 10yaml
operation: filter
parameters:
key: name
operator: icontains
value: "Demo"yaml
operation: filter
parameters:
key: name
operator: noticontains
value: "Demo"yaml
operation: filter
parameters:
key: line_item_ids
operator: arrcontains
value: "Item 42"Certain filter operators are "unary" filters, and thus do not require value to be present:
yaml
operation: filter
parameters:
key: deleted_at
operator: isnullyaml
operation: filter
parameters:
key: activated_at
operator: isnotnullyaml
operation: filter
parameters:
key: line_item_ids
operator: isemptyyaml
operation: filter
parameters:
key: line_item_ids
operator: isnotemptyPlease note that using filter with formula has the following form:
yaml
operation: filter
parameters:
key: total_amount
operator: ">"
value:
expression: add(minimum_amount + 100)
version: "1"Composite filters
Composite filters allow combining multiple regular filters using logical AND and OR operations. They serve as a way to create complex filtering conditions by chaining together simpler filters into a single composite expression.
Operand within composite filter can be either regular filter or another composite filter on its own.
Example: creating a filter equivalent of status == "cancelled" AND (total_amount == 0 OR is_test_payment == FALSE):
yaml
operation: filter
parameters:
operator:
type: and
operands:
- key: status
operator: "=="
value: cancelled
- type: or
operands:
- key: total_amount
operator: "=="
value: 0
- key: is_test_payment
operator: "=="
value: truederiveField
Add a new column to a result set using custom formulas.
| Parameter | Description |
|---|---|
field_name | Human readable name for the new column |
key | Technical key for the new column. It is used to reference this column in subsequent operations |
value.expression | Custom formula that will create the value for the column |
yaml
operation: deriveField
parameters:
field_name: Total Amount
key: total_amount
value:
expression: "amount + tax_amount"
version: "1"Example: here, the last column in dataset is calculated with the operation defined above.
| amount | tax_amount | total_amount |
|---|---|---|
| 100 | 20 | 120 |
| 80 | 5 | 85 |
addRelatedColumn
Adds a column from related model, defined as hasOne or hasOneThrough relation to the result set.
| Parameter | Description |
|---|---|
relation.key | Reference to a relation of current model |
key | Property key from a related model |
columns[].property.key | Technical key for the added column. It is used to reference this column in subsequent operations |
columns[].property.name | Human readable name for the new column |
yaml
operation: addRelatedColumn
parameters:
relation:
key: account
columns:
- key: name
property:
key: account_name
name: Account name
- key: created_at
property:
key: account_created_at
name: Account createdExample:
Given the users model returning the following data:
| user_id | account_id | |
|---|---|---|
| 1 | jane@test.host | 1 |
| 2 | tom@test.host | 1 |
| 3 | mary@test.host | 2 |
And account model returning:
| account_id | name | created_at |
|---|---|---|
| 1 | Account A | 2024-07-26 |
| 2 | Account B | 2024-12-12 |
The operation above will result in the following dataset:
| user_id | account_name | account_created_at | |
|---|---|---|---|
| 1 | jane@test.host | Account A | 2024-07-26 |
| 2 | tom@test.host | Account A | 2024-07-26 |
| 3 | mary@test.host | Account B | 2024-12-12 |
groupAggregate
Aggregates values on dataset produced by previous steps. It is used to:
- Calculate statistical measures (sum, average, min, max, count etc)
- Group data by fields in the dataset
| Parameter | Description |
|---|---|
aggregations | Array of aggregations, refer to aggregations section for details |
groups[].key | Group aggregates by the property of a result set |
groups[].precision | Grouping precision when grouping by date field. Must be one of "year", "quarter", "month", "week", "day_of_week", "day", "hour" |
groups[].fill | When grouping by date field, fill in the rows that would have missing values otherwise |
yaml
operation: groupAggregate
parameters:
groups:
- key: created_at
precision: month
fill: true
aggregations:
- type: count
property:
key: count_by_month
name: Count by month
- type: sum
key: total_amount
property:
key: sum_total_amount
name: Total amount
- type: max
key: amount
property:
key: max_amount
name: Max amountExample:
Given the following dataset:
| created_at | total_amount |
|---|---|
| 2024-04-10 | 100 |
| 2024-04-14 | 50 |
| 2024-04-21 | 50 |
| 2024-06-12 | 25 |
| 2024-06-17 | 50 |
| 2025-07-03 | 100 |
The operation above aggregates it into:
| created_at | count_by_month | sum_total_amount | max_amount |
|---|---|---|---|
| 2024-04-01 | 3 | 200 | 100 |
| 2024-05-01 | 0 | 0 | 0 |
| 2024-06-01 | 2 | 75 | 50 |
| 2024-07-01 | 1 | 100 | 100 |
relationAggregate
Aggregate values on a relation of current dataset.
| Parameter | Description |
|---|---|
relation.key | Reference to a relation of current model |
aggregations | Array of aggregations, refer to aggregations section for details |
filter | Filter conditions to apply on related dataset. See filter reference for details |
yaml
operation: relationAggregate
parameters:
relation:
key: order_line_items
aggregations:
- type: count
property:
key: number_of_items
name: Number of items
- type: sum
key: total_amount
property:
key: total_value
name: Total value
filter:
key: status
operator: "!="
value: cancelledExample:
Given the following values in order dataset
| order_id |
|---|
| order-1 |
| order-2 |
| order-3 |
And values in order_line_items dataset that is a hasMany relation of order dataset
| order_id | total_amount | status |
|---|---|---|
| order-1 | 100 | processed |
| order-1 | 50 | processed |
| order-1 | 50 | cancelled |
| order-2 | 25 | processed |
| order-2 | 50 | processed |
| order-3 | 100 | cancelled |
The operation above aggregates it into:
| order_id | number_of_items | total_value |
|---|---|---|
| order-1 | 2 | 150 |
| order-2 | 2 | 75 |
| order-3 | 0 | 0 |
switchToRelation
Jumps to a data returned from a model relation.
| Parameter | Description |
|---|---|
key | Reference to a relation of current model |
yaml
operation: switchToRelation
parameters:
relation:
key: usersExample:
Given the users model returning the following data:
| user_id | account_id | |
|---|---|---|
| 1 | jane@test.host | 1 |
| 2 | tom@test.host | 1 |
| 3 | mary@test.host | 2 |
And account model returning:
| account_id | name |
|---|---|
| 2 | Account B |
| 1 | Account A |
The operation starting from account model above will result in the following dataset:
| user_id | account_id | |
|---|---|---|
| 3 | mary@test.host | 2 |
| 1 | jane@test.host | 1 |
| 2 | tom@test.host | 1 |
Aggregations
yaml
type: count
property:
key: property_key
name: Property nameyaml
type: count_distinct
property:
key: property_key
name: Property nameyaml
type: sum
key: sum_by_key
property:
key: property_key
name: Property nameyaml
type: avg
key: average_by_key
property:
key: property_key
name: Property nameyaml
type: min
key: min_by_key
property:
key: property_key
name: Property nameyaml
type: max
key: max_by_key
property:
key: property_key
name: Property nameyaml
type: first
key: first_by_key
sort:
key: sort_key
direction: ASC # or DESC
property:
key: property_key
name: Property nameyaml
type: last
key: last_by_key
sort:
key: sort_key
direction: ASC # or DESC
property:
key: property_key
name: Property nameyaml
type: median
key: median_by_key
property:
key: property_key
name: Property nameyaml
type: metric
metricId: metric_id
property:
key: property_key
name: Property name